

 Desde que comencé a interesarme en el periodismo de base de datos, una de mis mayores preocupaciones se centró en la gran brecha que comenzó a abrirse entre los medios con mayores recursos, dispuestos a contratar a expertos en análisis de datos y programadores y los medios más pequeños, como los de provincia, que están muy lejos de esa realidad. Sin embargo, en el último año han aparecido herramientas gratuitas y de código abierto que hacen posible acceder a un componente esencial en este campo: la visualización de datos. Al principio no fue fácil: la mayoría de los recursos online no están disponibles en español, o requieren de ciertos conocimientos en programación que los periodistas en general no tienen, o bien es necesaria la descarga de un programa en la PC, hecho que en muchas salas de redacción representa una dificultad, ya que no todas las terminales, por cuestiones de seguridad informática, tienen habilitada esa opción. Datawrapper: creado por Mirko Lorenz, da respuesta a la necesidad de graficar a partir de hojas de cálculo en Excel, de una manera sencilla e intuitiva. Cualquier periodista aún sin experiencia ni entrenamiento previo, puede diseñar sus propios gráficos a partir de datos abiertos. Solo es cuestión de animarse y dar el primer paso.
Desde que comencé a interesarme en el periodismo de base de datos, una de mis mayores preocupaciones se centró en la gran brecha que comenzó a abrirse entre los medios con mayores recursos, dispuestos a contratar a expertos en análisis de datos y programadores y los medios más pequeños, como los de provincia, que están muy lejos de esa realidad. Sin embargo, en el último año han aparecido herramientas gratuitas y de código abierto que hacen posible acceder a un componente esencial en este campo: la visualización de datos. Al principio no fue fácil: la mayoría de los recursos online no están disponibles en español, o requieren de ciertos conocimientos en programación que los periodistas en general no tienen, o bien es necesaria la descarga de un programa en la PC, hecho que en muchas salas de redacción representa una dificultad, ya que no todas las terminales, por cuestiones de seguridad informática, tienen habilitada esa opción. Datawrapper: creado por Mirko Lorenz, da respuesta a la necesidad de graficar a partir de hojas de cálculo en Excel, de una manera sencilla e intuitiva. Cualquier periodista aún sin experiencia ni entrenamiento previo, puede diseñar sus propios gráficos a partir de datos abiertos. Solo es cuestión de animarse y dar el primer paso.
Categoría: Periodismo con bases de datos
NACION Data en Facebook

Desde hoy, el equipo de Periodismo de Datos de LA NACION tiene presencia en Facebook. Con el lanzamiento de nuestra fan page abrimos un nuevo canal de comunicación para estar más cerca tuyo y compartir noticias, videos, aplicaciones y ¡mucho más!
¿Por qué estamos en Facebook? Porque queremos escucharte, intercambiar experiencias, que conozcas nuestro trabajo y lo más importante: ¡que te sumes a la movida de los datos abiertos! Además, en este nuevo espacio podrás comentar las publicaciones, compartirlas y enterarte de las últimas tendencias mundiales en esta materia. Seguir leyendo
Declaraciones juradas: el detrás de escena de un gran trabajo en equipo
¿Cómo mostrar las declaraciones juradas de los funcionarios del Gabinete de manera simple? Esa fue la primera pregunta que nos hicimos cuando comenzamos el proyecto. Así, luego de 4 meses de intenso trabajo, la semana pasada lanzamos una aplicación interactiva que te permite consultar un gran volumen de información, en forma amigable y con la posibilidad de ver los documentos originales.
El resultado combina periodismo, diseño, data mining y programación. Por eso, el proyecto involucró a 3 áreas y más de 10 personas con perfiles muy diferentes.
Center for Investigative Reporting: datamining, salud y fraude.
Les presento a Chase Davis (@chasedavis), periodista y ex Director Tecnológico del Center for Investigative Reporting.
En el video nos contó la historia de su carrera profesional, su pasión por aplicar tecnologías nuevas a bases de datos y cómo trabajan con la comunidad de Data Science en San Francisco ¡No se lo pierdan! (Tiene subtítulos en español).
Desde enero 2013, hace unos pocos días, dejó su posición trabajar en consultoría, dar clases y dedicarle tiempo a algunos proyectos personales.
Entre sus casos favoritos de su paso por California Watch y el CIR, mencionó Decoding Prime en el que trabajaron en conjunto con el ganador del Pulitzer Steve Doig, de la Walter Cronkite School of Journalism, en la Universidad de Arizona.
Hemos traducido un capítulo del DataJournalism Handbook donde el mismísimo Steve Doig explica el caso. ¡Los dejo con el experto! Seguir leyendo
Tenencia de armas en Estados Unidos: guerra de data

Fuente:Lohud.com
¿Qué harías vos si te enteraras de que varios vecinos de tu misma cuadra ―o edificio―tienen un arma? O que esa misma persona que te saluda con una sonrisa respetuosa todas las mañanas cuando te la encontrás en la puerta del edificio, duerme con una ametralladora bajo su almohada. ¿Es información que quisieras saber? ¿Qué harías al enterarte de esto? ¿Evitarías pelearte con tu vecino por cualquier nimiedad y le darías la razón en todo? O vos también, comprarías un arma para protegerte. Seguir leyendo
Cómo usar OpenRefine para trabajar una base de datos

Por Natalia Sampietro(*) (**)
Cuando trabajamos con datos buena parte de nuestros esfuerzos y tiempo se va en el acondicionamiento, limpieza y puesta en orden de los mismos. Problemas de codificación, estándares, delimitadores, errores de tipeo, entre otros, se convierten en uno de los primeros obstáculos a superar en el camino hacia la generación de información de calidad.
En la búsqueda de una herramienta que simplifique ese camino nos encontramos con Open Refine, antes conocido como Google Refine, un producto de código abierto que ofrece múltiples funcionalidades que van desde limpieza, organización y transformación en diferentes formatos, hasta la posibilidad de extender los datos a través de web services y relacionar con bases de datos como Freebases. Seguir leyendo
Mar Cabra: “La fuente de un periodista también puede ser una base de datos”

Foto: Antonio Delgado
Mar Cabra (@cabralens) es una de las periodistas de investigación y bases de datos más prestigiosas de España. Integra el International Consortium of Investigative Journalism (una asociación internacional de periodistas de investigación) y dirigió hasta diciembre de este año Civio, un colectivo sin fines de lucro que “busca fomentar la cultura de la transparencia y el acceso a la información pública, así como una ciudadanía activa e implicada”. Entre sus proyectos se destacan España en llamas.
En la actualidad, la periodista (que trabajó para la BBC, CNN+, El Nuevo Herald/The Miami Herald y laSexta Noticias, además de publicar investigaciones en International Herald Tribune, Le Monde, El País, El Mundo y PBS) es una voz autorizada para hablar de innovación en periodismo de datos, una actividad profesional que también llevó al plano académico, ya que hace algunos meses es integrante del cuerpo de profesores de la flamante Maestría en Periodismo de Investigación, Datos y Visualización de la Escuela de Periodismo y Comunicación de Unidad Editorial y la Universidad Rey Juan Carlos.
En una entrevista exclusiva para NACION Data, Cabra asegura que hay que adaptar las habilidades profesionales tradicionales a los nuevos tiempos, que en las bases de datos se pueden encontrar grandes historias periodísticas, y que es esencial bregar en cada país por una ley de acceso a la información pública que se cumpla sin condicionamientos.
– ¿Por qué la vieja tradición del periodismo de investigación se potencia a partir de las iniciativas de apertura de datos?
– Para hacer un buen periodismo de investigación siempre se habla de seguir el rastro de papel. Hoy en día, ese rastro ya no solo circula en hojas que se mueven de oficina en oficina, sino de manera electrónica -y sobre todo en bases de datos-. Ahora las herramientas tecnológicas nos permiten comprender esas grandes cantidades de información fácilmente, y es por eso que a nuestra labor de periodistas de descubrir lo oculto se suma el analizar datos. Así que toda iniciativa que fomente la transparencia de datos, como el movimiento de Open Data, es muy útil para el periodista.
LN Data en ProPublica

Con post firmado por editor de aplicaciones de noticias, Scott Klein, el sitio de ProPublica -uno de los principales referentes del periodismo de investigación sin fines de lucro- informó que Ricardo Brom, integrante del equipo de LA NACION Data, se sumó a su Pair Programming Project (P5).
“Ricardo trabaja con el excelente equipo de periodismo de datos de LA NACION, cuyos recientes proyectos de investigación han incluido un análisis de los subsidios al transporte público de pasajeros -que refleja que los subsidios a los combustibles son lo suficientemente grandes como para cada bus pueda funcionar en el sistema durante más de 24 horas por día-, así como una investigación que plantea preguntas acerca de la exactitud de la tasa de inflación oficial publicada por el gobierno argentino, que mostró que es la mitad que la calculada por consultoras independientes y la oposición”, dice la entrada de Klein.
El DataFest desde adentro

Durante las dos jornadas que duró el Datafest pude compartir la experiencia de vivir personalmente un evento en el que participé desde el comienzo hace casi 9 meses.
La variedad de disciplinas y ámbitos de los participantes, sumado al trabajo en conjunto se convirtieron en un disparador de ideas que se fueron concretando en cada uno de los proyectos presentados.
Pude participar y colaborar, como así también, aprender con las preguntas y enfoques de los diferentes equipos mientras recorría las mesas.
Ya en el segundo día, uno de los grupos, que había trabajado en Justicia, necesitaba visualizar las conclusiones a las que habían llegado. Luego de contarme la mirada que querían darle, comenzamos a probar distintas visualizaciones en Many Eyes y Tableau Public.
Aquí en unas líneas, Ariel Neuman nos cuenta en qué consistió el proyecto:
“El equipo de Justicia que trabajó durante el Datafest se concentró en tres ejes de trabajo, tomando como punto de partida la base de sentencias de las Cámaras de Apelaciones del Poder Judicial, disponibles en el sitio web del Centro de Información Judicial (CIJ), que cuenta con más de 162.000 fallos.
Por un lado, se hizo una depuración de sentencias del fuero comercial, para distinguir entre salas de asignación y partes involucradas en los procesos, con la intención de analizar la existencia o no de parámetros para la asignación/sorteo de causas.
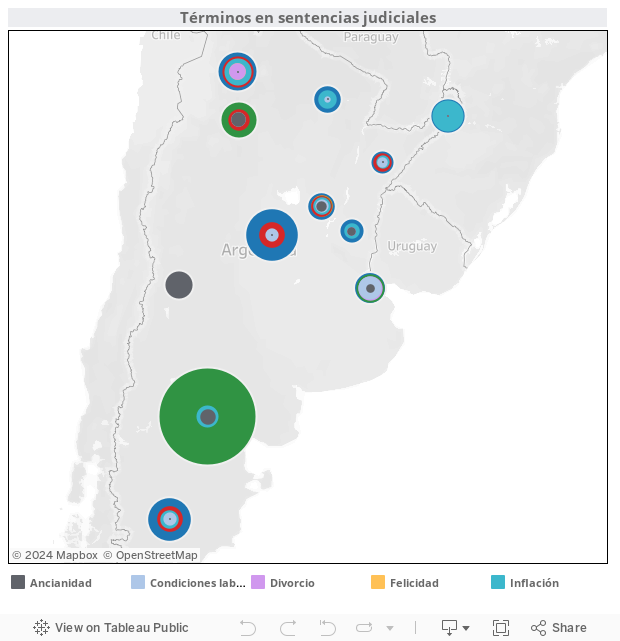
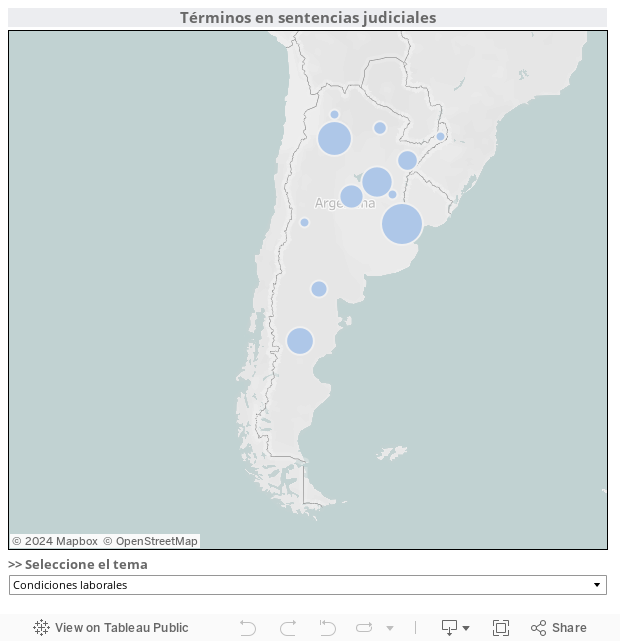
Un segundo eje de trabajo consistió en relevar los “principales temas que preocupan a los argentinos”, según TNS-Gallup, y rastrear si los conceptos más representativos (inseguridad, desempleo, pobreza, felicidad, soledad, etc.) se encuentran reflejados en las sentencias de las Cámaras de todos los fueros de todo el país.
Con los resultados se elaboró un mapa de visualización que diferencia la presencia de los mencionados términos en las diferentes jurisdicciones”.
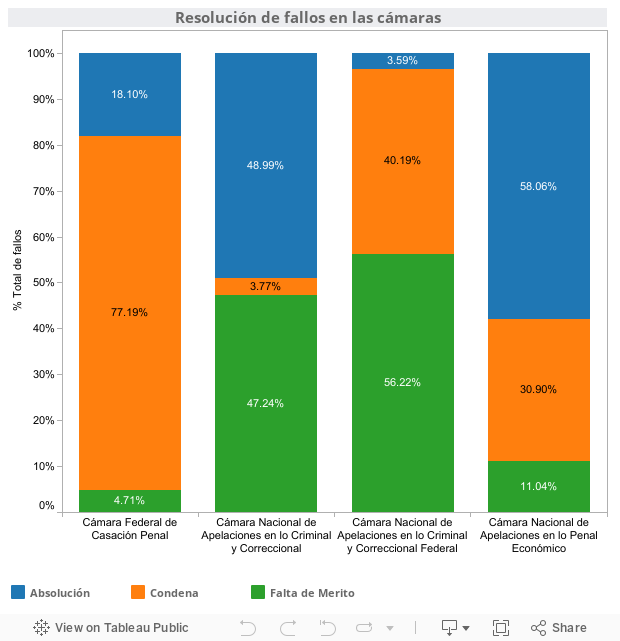
La tercera línea de investigación consistió en relevar los porcentuales de sentencias condenatorias, absolutorias y que declaran la falta de mérito en las Cámaras de Apelaciones en lo Criminal y Correccional, Criminal y Correccional Federal, Penal Económico y de Casación Penal.
Se advirtió una fuerte presencia de resoluciones en las que se dicta la falta de mérito, dato que debe ser contextualizado teniendo en cuenta que las sentencias relevadas corresponden no a una primera, sino a una segunda instancia judicial.
En este equipo también participaron entre otros: Otto Wald, Irina Moldavsky, Diego Melamed y Ariel Neuman.
Luego de todas las presentaciones, las corridas previas, todas las reuniones, todas las ideas, los Censothones (reuniones internas para normalizar los datos del Censo) y todo el entusiasmo que pusimos, puedo decir que mis expectativas fueron mucho más que superadas:
¡Tarea más que cumplida!
California Watch: datamining, corrupción, escuelas y terremotos
Les presento a Agustín Armendariz (@agustinCW), de California Watch, redacción ganadora de un premio a la Excelencia en Periodismo Digital otorgado por la Online News Association (2012).
Agustín es periodista y experto en datamining. En el video nos contó la historia de su carrera profesional, quienes fueron sus mentores, su pasión por los datos y ejemplos concretos de cómo trabaja con millones de registros y cartografía. ¡No se lo pierdan! (Tiene subtítulos en español)
Sobre “ On Shaky Ground” (Sobre terreno movedizo)
El proyecto On Shaky Ground mencionado durante la entrevista, tuvo por objetivo prevenir situaciones de desastre preservando la vida de los ciudadanos californianos, en especial niños en edad escolar. Su envergadura e impacto lo convirtió en finalista para el premio Pulitzer 2011, en la categoría de Local Reporting.

A partir de la serie de notas se reveló la existencia de falencias del Estado de California en velar por la seguridad de las escuelas públicas ante sucesos de terremotos.