


Flickr/CC/Social Blz Solutions
Por Ernesto Surijon Frimis *
Cuantas veces nos dijeron –”¡Vivís en una nube !” …
Hoy vamos a conocer una “nube de palabras”.
El correo electrónico suele ser un fiel referente de nuestra actividad diaria, nos muestra en alguna medida cómo estamos invirtiendo el tiempo y qué temas estamos abordando.
Un interesante modo de revisar nuestra gestión, es permitirnos monitorear los mails enviados / recibidos y analizar su contenido.
Podemos descubrir cuáles son los temas que nos demandan más mails y, por lo tanto, más tiempo de nuestra gestión.
La propuesta en este artículo es utilizar una herramienta para analizar la información de nuestro mail.
Elegimos uno de nuestras herramientas preferidas, llamada “R”, para que nos ayude a través de sus herramientas de text-mining.
Nos proponemos crear una “nube de palabras”, un gráfico elegante y ágil que nos va a mostrar cuales son las palabras más frecuentemente utilizadas.
Vamos primero al correo…
En nuestro caso utilizamos Outlook como software de correo.
Podemos exportarnos la información de los mails de un determinado lapso de tiempo, para el ejemplo tomaremos un mes.
En el Outlook tipeamos <CTRL><SHIFT><F>, nos presenta la pantalla de búsqueda avanzada
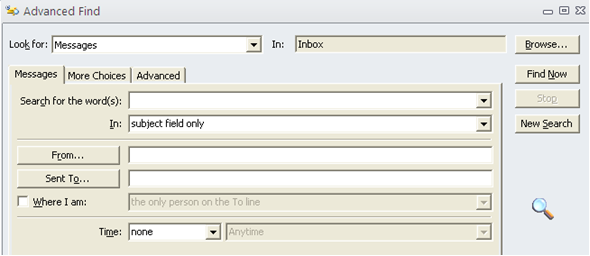
Vamos a la solapa de “Advanced”
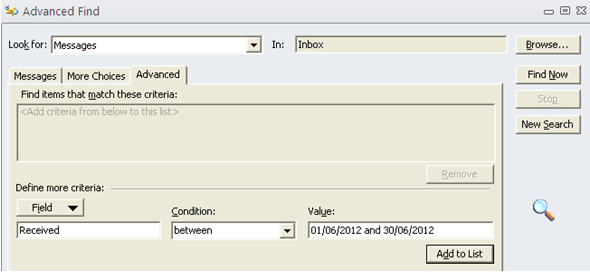
Clickeamos sobre el add to List ,
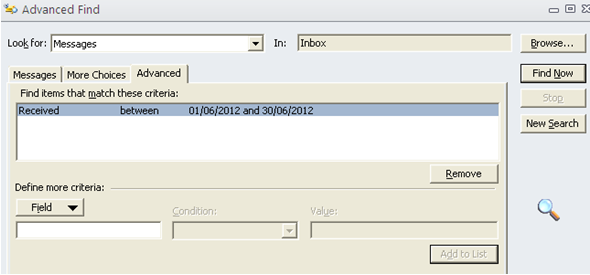
Y luego efectuamos el find….
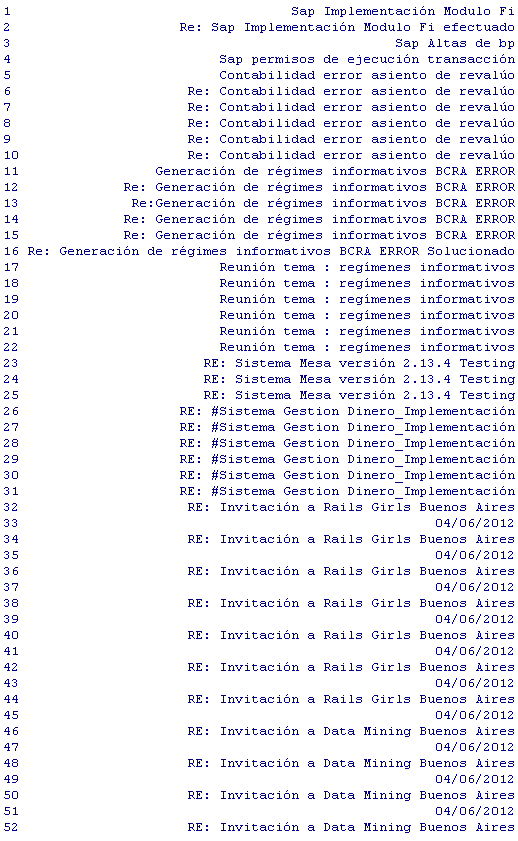
Sobre el resultado, tomamos la columna Subject.
Generamos entonces la información de los “Subject” de los mail en un archivo de texto.
En nuestro caso creamos el archivo d:temprsubject_mail.txt, mostramos un extracto de la información
Luego nos dirigimos al R y lo tratamos (vemos la consola de trabajo de R)

# leemos el archive con los mails
mail <- read.csv(“d:/temp/r/subject_mail.txt”,header=T)
# creamos un corpus
mail.corpus <- Corpus(VectorSource(mail[1]))
# removemos puntuaciones y palabras específicas
mail.corpus <- tm_map( mail.corpus,removePunctuation)
mail.corpus <- tm_map( mail.corpus,function(x)removeWords(x,stopwords()))
#Calculamos la frecuencia con que aparecen las palabras
tdm <- TermDocumentMatrix(mail.corpus)
#armamos una matriz con la frecuencia de palabras
m <- as.matrix(tdm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
wordcloud(d$word,d$freq)

Con nuestra nube de los años 80 generada, (blanco y negro) nos ponemos a pensar que podemos mejorarla para hacerla más legible.
#Le ponemos un poco de color a nuestra “nube de palabras”
wordcloud(d$word, d$freq, random.order=FALSE, colors=brewer.pal(8, “Dark2”))
De esta manera , con la era color logramos nuestro cometido…

La visualización está bastante más lograda, con un simple golpe de vista tenemos la foto de nuestra actividad.
Claramente distinguimos la palabra “error” como la más frecuente, en un color gris y con el mayor tamaño, ( danger !, estamos en problemas ), luego entre otras vemos una serie de palabras en fuxia : bloomberg, invitación , planilla etc, mismo color y tamaño nos indica que se presentan con la misma frecuencia.
Para entender un poco el contexto, comentamos que los mails en el ejemplo corresponden a un área de desarrollo de sistemas.
Entre las top Word encontramos: error, contable, sistema, contabilidad, gestión.
La palabra “error”, tiene una fuerte presencia, desgraciadamente estamos teniendo muchos errores en los sistemas, estamos dedicando mucho tiempo a temas contables y menos a gestión , nuestra “nube” nos lo está alertando, es probable que debamos mejorar la calidad para evitar errores y aumentar nuestro tiempo de gestión.
Podemos jugar con los sombreros, y colocarnos uno más tradicional y analítico.
Hecho esto cambiamos nuestra forma de visualización de la información, disponemos ahora de un gráfico (x,y) , tipo Gantt .
Sobre el eje y, reflejamos las palabras, y sobre el x, la frecuencia.
Se lo indicamos a R:
library(ggplot2)
qplot(names(v), v, geom=”bar”) + coord_flip()
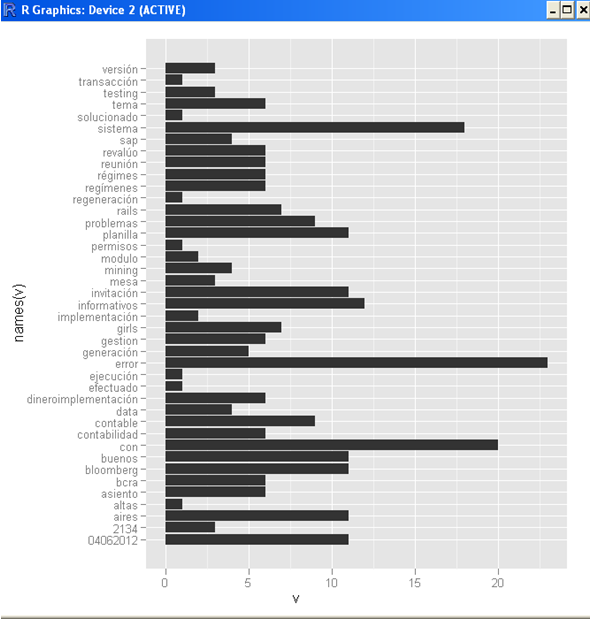
Nos quedó algo desordenada las barras, así que vamos a girarlo y mostrarlo ordenado para agilizar su análisis
Una sentencia…
barplot(v, las=3)
Chan… ¡ya está! Rápido, ¿no ?
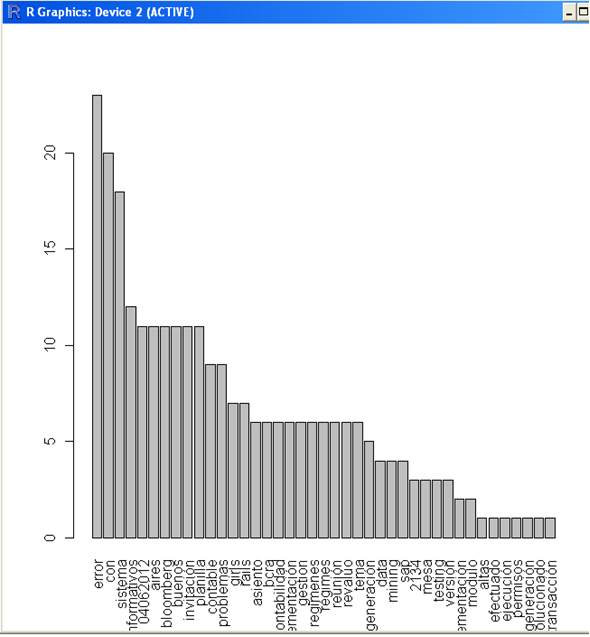
¡Ahora sí! Vimos ágilmente con R cómo analizar información de texto y qué se nos dice entre líneas si buceamos un poco.
En este caso, tomamos nuestros mails, pero podemos aplicarlo a un documento, un articulo , el contenido de una página web, información de redes sociales – Twitter, Facebook etc,
Tengamos cuidados entonces antes de escribi , alguien puede estar analizándonos…
Sobre R
R es un lenguaje y entorno de programación para análisis estadístico y gráfico. Se distribuye bajo la licencia GNU GPL y está disponible para los sistemas operativos Windows, Macintosh, Unix y GNU/Linux.
Ha tenido la ventaja de contar con el apoyo de famosos estadísticos y científicos tales como Hastie, Tibshirani, Friedman, Ripley, Venables, etc. Muchos han contribuído con nuevas y novedosas rutinas para implementar nueva metodología estadística, lo que lo coloca como uno de los programas de avanzada para investigadores en estadística.
Básicamente es un lenguaje de scripting (en cierta medida similar a otros como Perl,Phyton,etc ), pero orientado a resolución de temas estadísticas.
Es escalable a través de librerías de última generación que se bajan gratuitamente de internet y potencian el lenguaje.
Es uno de los lenguajes más utilizados por la comunidad estadística, cuenta con innumerables librerias que cubren los más variados campos de la investigación y análisis de la información
Algunos de los campos que aborda: estadísitica bayesiana, aplicaciones financieras, geoestadística, series cronológicas, clustering, text-mining, data-mining,etc.
Actualmente se encuentra entre los top-20 lenguajes más utilizados.
The New York Times, publicó recientemente un artículo donde comenta el crecimiento de usuarios de R, destacando su uso en gigantes como Dell, Hewlett-Packard o IBM ,Pfizer, Merck, Google, el InterContinental Hotels Group, Bank of America o Shell.
* Ernesto Surijom Frimis (@Esurijon) es licenciado en Sistemas (CAECE) y realizó Posgrados en Dirección de Sistemas (UB), Marketing (UADE) y Finanzas (UADE). Cuenta con más de 20 años experiencia en la industria de software (Bancos y Telecomunicaciones).
+ Info
http://cran.r-project.org/ (sitio oficial)
http://knuth.uca.es/R/doku.php?id=r_iki
http://es.wikipedia.org/wiki/R_(lenguaje_de_programacion)
r- users group
http://rwiki.sciviews.org/doku.php?id=rugs:r_user_group
Comunidad r-hispano