


Flickr/Ben Sutherland – CC Attribution
Podríamos considerar como caso “histórico” de Periodismo de Base de Datos el de las “MP’s Expenses” de The Guardian.
El 8 de mayo de 2009, The Telegraph comenzó a publicar notas relativas a gastos presentados a reembolso por los ministros parlamentarios. La información la obtuvo de una fuente non sancta a la que pagaron £ 110.000.
El 18 de junio el Parlamento inglés publicó en su sitio oficial un informe más detallado de los reclamos de gastos luego de una larga batalla de requerimientos de información en base a la Freedom of Information Act.
Destacaremos cuestiones relacionadas con la gestión de información que realizó The Guardian a partir de dicha publicación oficial.
A) la construcción de una aplicación orientada a interactuar con la audiencia para recoger información relevante de los reclamos de reembolso (via “crowdsourcing”)
B) la conformación de la base de datos principalmente a partir de los aportes de la audiencia.
C) la puesta a disposición de la base obtenida en planillas símil Excel (Google Spreadsheets) para que otros puedan trabajar con los datos.
D) las visualizaciones realizadas por Tony Hirst a partir de la combinación de herramientas de procesamiento como Yahoo Pipes y de visualización como Many Eyes y Google Maps.
E) los principios relacionados al Periodismo de Base de Datos: #OpenGov, #Crowdsourcing, #OpenData, #Scraping y #DataViz
A. Una aplicación para crowdsourcing
Para ganar tiempo en el procesamiento de la información frente a los las semanas de ventaja que le llevaba su competidor, The Guardian desarrolló una aplicación integrada al sitio principal donde se alojaron más de 400.000 PDFs escaneados para que la audiencia ayudara a clasificar los reclamos de reembolso y señalara posibles líneas de investigación a la redacción.
En una segunda entrega de información por parte del Parlamento (aproximadamente 40.000 PDFs), The Guardian mejoró el desarrollo de su aplicación a partir de la experiencia recolectada en junio y meses subsiguientes.
Realicé un videotour de ambas aplicaciones con explicaciones en español de las principales características. Recomiendo que lo vean en pantalla completa pues la filmación es en HD.
Lo pueden ver también HD en Youtube.
Dos integrantes de aquel equipo han publicado en sus blogs personales sobre sus respectivas experiencias volcando información técnica y autocríticas: Simon Willison y Martin Belam. ¡Imperdibles!
El primero, Simon Willison -Technical Architect en el GUARDIAN hasta julio de 2010-, fue entrevistado por NiemanLab en el lanzamiento de la primera aplicación de PDFs.
De sus dichos, extraigo lo siguiente:
- Utilizaron DJANGO como framework, plataforma desarrollada por el mismo Simon durante 3 años junto a Adrian Holovaty.
- Alojaron (hosting) la aplicación en Amazon EC2. Aron Pilhofer en un comentario destacó las bondades de este servicio y la experiencia de uso en el NYTimes.
El otro integrante del equipo Martin Belam, Lead User Experience & Information Architect, frente a críticas propias y ajenas, destaca varias áreas donde el proyecto fue un claro éxito.
- El equipo técnico en una semana desplegó una aplicación en la nube que luce totalmente integrada al sitio, utilizando tecnología que no era de uso corriente en el medio.
- Reunieron un equipo conformado por staff multidiciplinario de diseño, editorial, tecnología y control de calidad para lanzar un proyecto de esta envergadura en los tiempos que la noticia requería.
- Han aprendido y mejorado. Cuando el segundo lote de documentos fue puesto a disposición, el equipo que trabajaba en la aplicación, descompuso las tareas en otras más pequeñas lo cual logró producir la sensación de misión cumplida a los usuarios contribuyentes, facilitando la participación y el cumplimiento total del objetivo.
B. El desarrollo de la Base de Datos con el aporte de la audiencia
El tweet de cuando arrancaron:
After 90 mins, 1700 users have audited MPs expenses using our crowdsourcing tool. We can’t get them up fast enough! http://bit.ly/156PYO
— janinegibson (@janinegibson) junio 18, 2009
En la primera serie llegaron a participar 20.000 usuarios.
La DATA que se conformó con la ayuda de los lectores incluyó:
- fechas
- montos
- tipo de gasto
- tipo de documento
Del primer set de 400.000 PDFs, la audiencia solo llegó a revisar la mitad. No obstante Paul Lewis dice que desde el punto de vista periodístico sí fue un éxito porque los ayudaron a relevar más de 200.000 PDFs en corto tiempo y efectivamente la audiencia acercó historias a la Redacción.
Del segundo set de PDFs, lograron que fueran revisados en su totalidad a través de las mejoras en desarrollo conceptual de la aplicación.
La entrevista de NiemanLab a Willison en la fase inicial del proyecto es muy buena, pero me parece más enriquecedor lo que Simon escribió en su blog personal sobre el aprendizaje del equipo aplicado a la segunda etapa del proyecto.
A partir de los errores cometidos en los dos proyectos, Simon Willison recomienda:
– Asegurarse de realizar la pregunta correcta a la audiencia
– No dejar de retribuir las contribuciones de los usuarios
– Exponer la mayor cantidad de información posible a los periodistas durante el proceso de armado de la base.
– Configurar el proceso de “Próximo hecho a revisar” en forma más sólida y rotunda.
C. The Guardian pone a disposición del público la base de datos obtenida.
En abril de 2009, un par de meses antes de la puesta en marcha de la aplicación para “crowdsourcing“, The Guardian lanzó su DataBlog (via Simon Rogers)
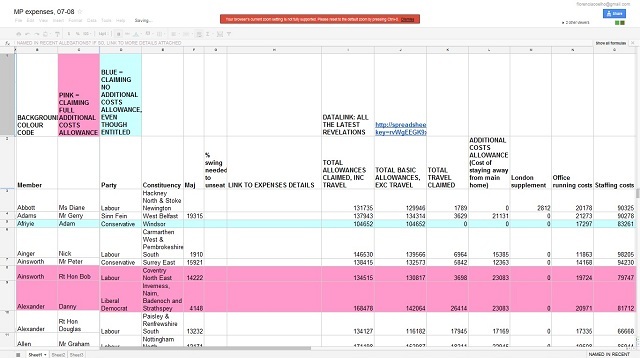
Ya desde abril habían empezado a publicar información existente de las “MPs Expenses” (anterior a la publicación oficial ampliada de junio) poniendo la base de datos obtenida a disposición en formato Google Spreadsheets.
@Datastore anunció la publicación de la base de datos con los números de 2008/9, invitando a los lectores a realizar visualizaciones:
D. Las visualizaciones de Tony Hirst
Y Tony Hirst fue de los primeros en recoger el guante.
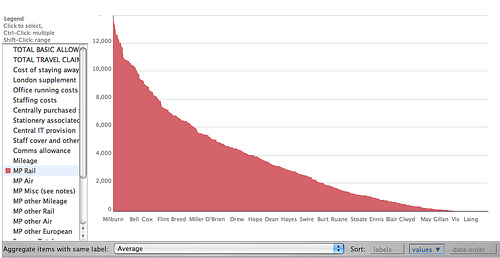
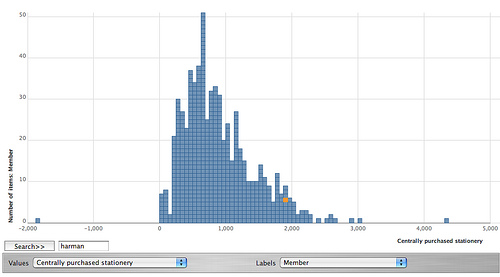
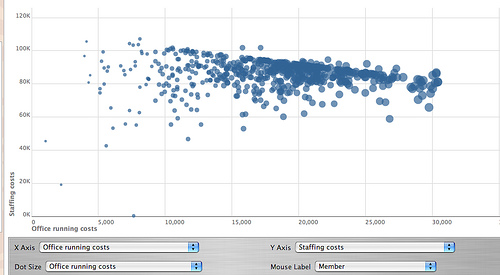
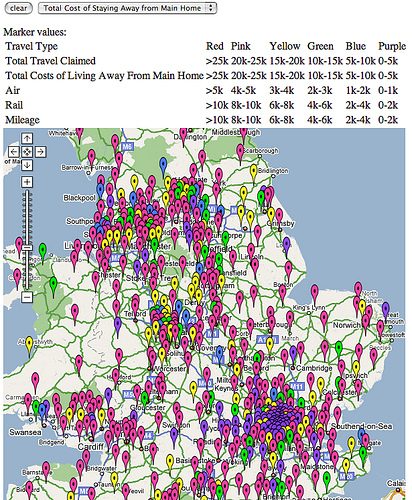
A partir de las primeras planillas que armó The Guardian, Tony resolvió experimentar con Many Eyes, el servicio de visualizaciones interactivas desarrollado por IBM.
Como la base de datos contenía el símbolo del Pound (£), tuvo que realizar acciones de limpieza de los CSV. Lo resolvió usando YahooPipes.
Al compartir sus visualizaciones, Tony se sintió desafiado por Charles Arthur de The Guardian a mapear la información de Gastos de Viaje cuyo reembolso solicitaban los Ministros Parlamentarios, desde Westminster hasta sus hogares de origen.
Entonces también realizó una serie de Google Maps
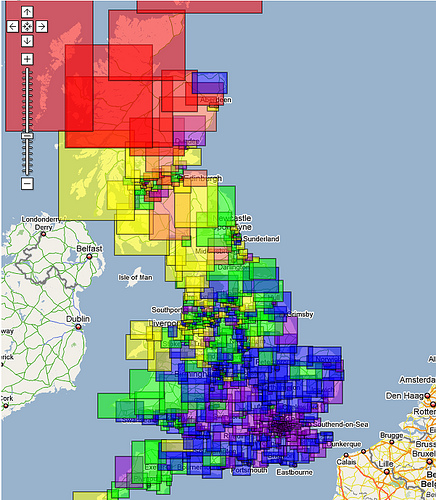
Y luego realizó éste con superposiciones de capas.
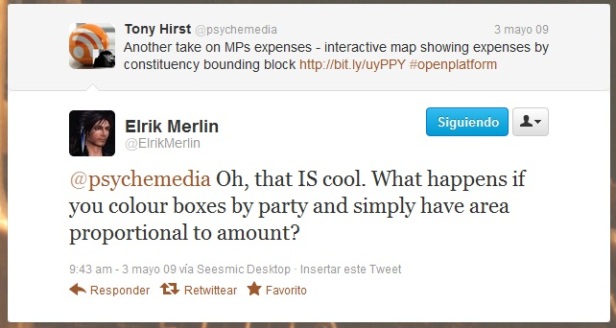
Y alguien más lo desafió a correr los límites coloreando la información por origen partidario de los ministros y relacionando el área proporcional a los montos reclamados.
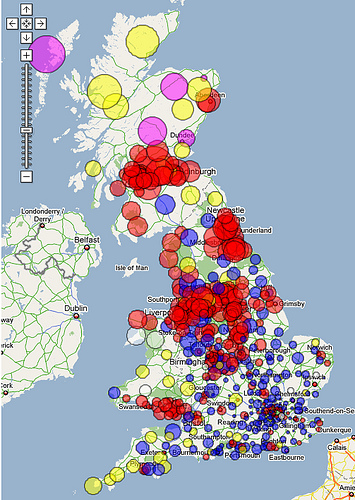
Sus visualizaciones, junto con las de otros usuarios, fueron publicadas en el Data Blog.
Les dejo una frase para conocer más a Tony Hirst:
“… qué aprendieron a hacer hoy por primera vez? Mi dia generalmente no empieza hasta que haya surgido un problema y logre resolverlo. Eso quizas explique porque no soy productivo en un sentido corporativo/institucional en modo alguno …”
¡Me encanta! Y yo también enfrenté un desafío. 🙂
Dado que las visualizaciones de Tony en Many Eyes Wikified están deshabilitadas, subí a Many Eyes “classic” el spreadsheet. ¡Tardé menos de cinco minutos en publicar un gráfico interactivo! No logré embeberlo pero al clickear en la imagen acceden al mismo.


E) Periodismo de Base de Datos: #OpenGov, #Crowdsourcing, #OpenData, #Scraping, #DataViz
Reconozco que este post fue un recorrido largo pero creo que valió la pena.
El caso de MPs Expenses -si bien es de 2009 y ya hay muchos avances en varios aspectos al día de hoy-, es muy ilustrativo para ver actuar en forma conjunta varios principios relacionados con el Periodismo de Base de Datos.
Open Government (#OpenGov) : el movimiento pro Gobierno Abierto -transparente- forzó al Parlamento inglés a extender el alcance de la información brindada oficialmente frente a requerimientos basados en la Freedom of Information Act (FOIA).
Crowdsourcing: el trabajo del medio con la audiencia para agilizar los tiempos de relevamiento de información instrumentado mediante una aplicación ad hoc.
OpenData: The Guardian pone a disposición del público en su blog las planillas de Google Spreadsheets elaboradas durante todo el proyecto para que los usuarios las combinen, mezclen, filtren y realicen visualizaciones.
Scraping de Datos: una de sus variantes vía el reformateo de los datos que realizó Tony Hirst para hacerlos compatibles con Many Eyes, utilizando Yahoo Pipes.
Visualización de Datos (#DataViz): las visualizaciones de Tony realizadas mediante herramientas gratuitas y de fácil uso como son Many Eyes y Google Maps.
Después de todo esto, ¡triunfó el bien! A partir del esfuerzo de tantas partes que arrojaron luz sobre este caso, los contribuyentes recuperaron £500,000 y tienen Ministros Parlamentarios más cuidadosos desde entonces.
+ Info:
Videos de Simon Willinson explicando MPs Expenses (2009)
http://www.youtube.com/watch?v=yCBy2p9jLPA
http://www.youtube.com/watch?v=m6X46YsqFuI
http://www.youtube.com/watch?v=6er9XgZ2hZM
http://youtu.be/nhlc4spbHx4
“Crowdsourcing Application” con los mails de Sarah Palin (2011)
http://www.guardian.co.uk/world/sarah-palin-emails