
Trap is one of the most popular music genres among young people in Argentina recently: of the most listened artists last year, ten of them swung between Rap, Trap and Reggaeton. We wanted to use Natural Language Processing (NLP) tools to analyze their lyrics, demystify the concepts around the genre and understand what these artists, who bring about such a furor among the new generations, are talking about.
This is a development made by LA NACION Data that took approximately seven months to complete and it is part of an experimentation process with new technologies for journalistic production.
One of the great challenges of this project was the application of techniques to texts written in prose to texts written in verse, with phrases in different languages (English, Spanish, Italian, among others) and words and abbreviations specific to the genre not found in dictionaries.
The whole information process was made in Python and R. Visualizations were made in Vue.JS.
In this text, we will describe the different steps of the process, the metrics used, and the treatment of the data.
Data source
First step: a total of 692 songs were scrapped, selected from twenty main artists of the genre (Duki, Paulo Londra, Lit Killah, Neo Pistea, Ysy A, Lucho SSJ, Homer el Mero Mero, CRO, Zaramay, Cazzu, Nicki Nicole, Khea, Trueno, Ca7riel and Paco Amoroso, Wos, Ecko, Chita, Seven Kayne, Acru, Tiago PZK) until November 2020 from Genius. All these names were selected by journalists specialized on this topic.
Pre-processing
After the selection of these song lyrics, different pre-processing steps ‒tokenization and lemmatization‒ were taken to calculate the frequency of words used in the songs. To clean words, Stopwords library for Python was used and onomatopoeia was unified under the word “Yeah”.
As regards term frequency counting, Collections library was used from the same programming language.
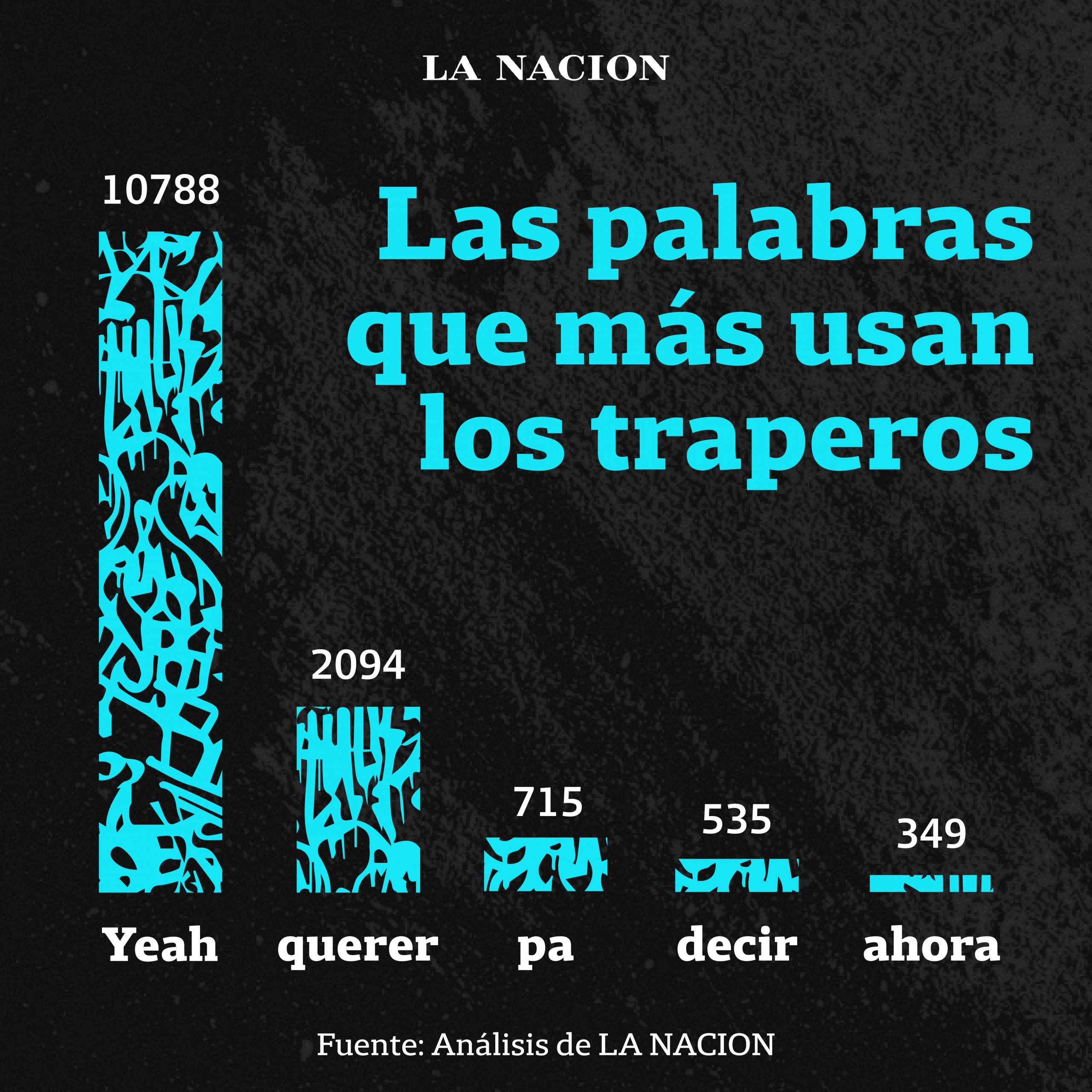
A stemming technique was tried on, but it was ruled out later as it was not so accurate as lemmatization.
These same steps were programmed in R language to check results and several repetitions were carried out on the model to improve results.
Brand names, persons and places: Named Entity recognition (NER)
We used SpaCy library in Spanish, and it was manually checked.
A sample of songs was taken with a 95% confidence interval and it was manually classified word by word under three labels: places, persons and brand names to compare then the manually labeled entities against those recognized by the model.
Error analysis was then performed to understand those cases where the model did not recognize the manually labeled entities.
After several repetitions, the EntityRuler, a SpaCy’s functionality, was used to add entities and improve entity recognition. For the EntityRuler, different Wikipedia web pages with lists of tags were used to train the model.
Thus, the model was run once again on the sample to perform a confusion matrix and determine the F1 score (metric to know the accuracy of the classification model), that was 0.61 in its latest version.
Finally, the universe of all lyrics was processed and, once the output was achieved, a manual correction was performed on it to achieve an even higher level of accuracy.

For this step, other libraries such as NLTK or Stanford CoreNLP were evaluated but did not achieve an acceptable level of accuracy as SpaCy.
Self-reference and exo-reference index
For this step, the preprocessing tokenization was used as input. Unlike the word frequency calculation, regular expressions were used to find the number of times an artist mentions himself and others.
The different ways in which an artist can be called were considered. For example, Duki, in addition to being called “Duki”, can be called “Duko”.
Topic detection

The technique known as Topic Modelling was applied with the Top2Vec model, which automatically detects topics by generating topic vectors, documents and words.
Other models (LDA, LSA) were also tested for this step, but they did not show as much accuracy as the one finally used. And, it is the only model that worked on not so large volumes of data as the ones we worked with.
Clustering with KMeans
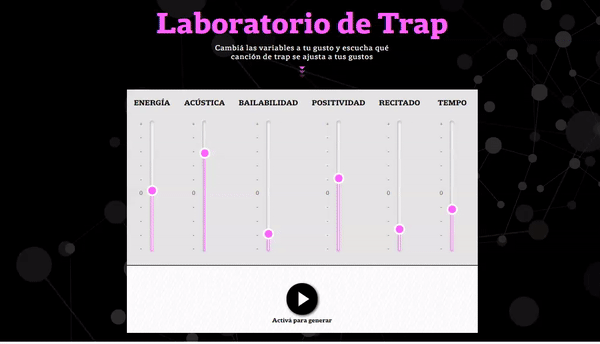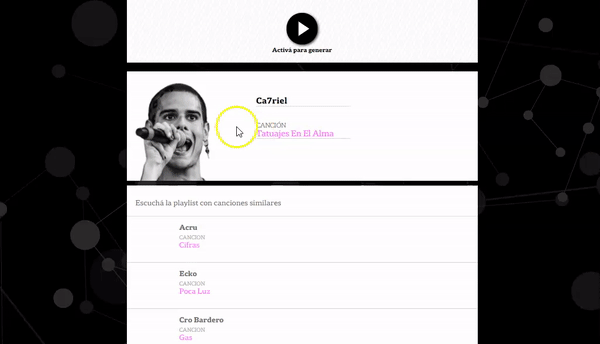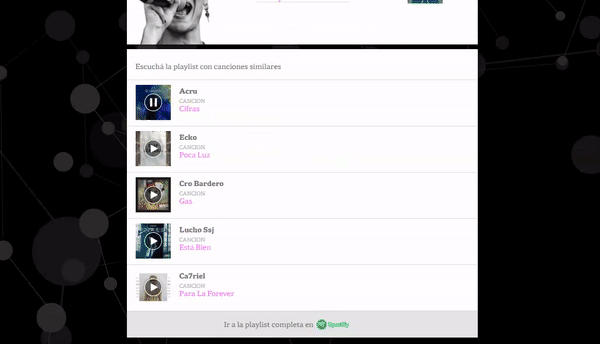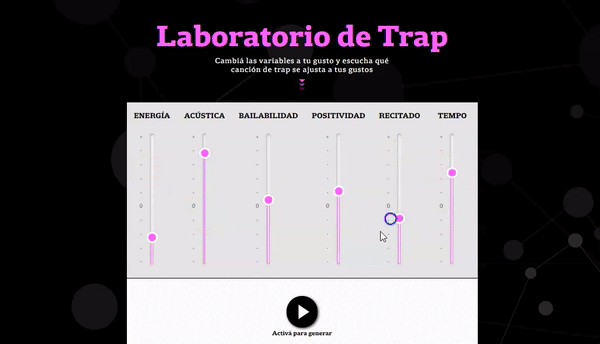
Unlike the previous steps, variables related to the rhythm of each song (danceability, tempo, energy, acoustic level) were used as input of the Spotify API.
Based on these variables, a technique known as ‘clustering’ was used with the KMeans model, that segments variables from a dataset homogeneous among themselves and heterogeneous with the rest.
Different numbers of clusters were tested (three to six), but it was concluded that three was the optimal number of clusters between similar and separating between different ones.