>>> PREVIOUS: Subsidies to the Argentina´s movies industry 2008-2014

Scrapping and building this dataset from scratch by Ricardo Brom
-
We build this data set from 2008 , and today we keep it updated
-
these are more than 70 PDF files
-
some PDFs are monthly, some annual and some cover a whole semester
Some challenges:
PDF´s had different formats and different data design for example: some had 5 columns:

while others had 4 columns:

Some had TOTALS:

but others didn´t have TOTALS:o:

After solving this problems we obtained the excel dataset:
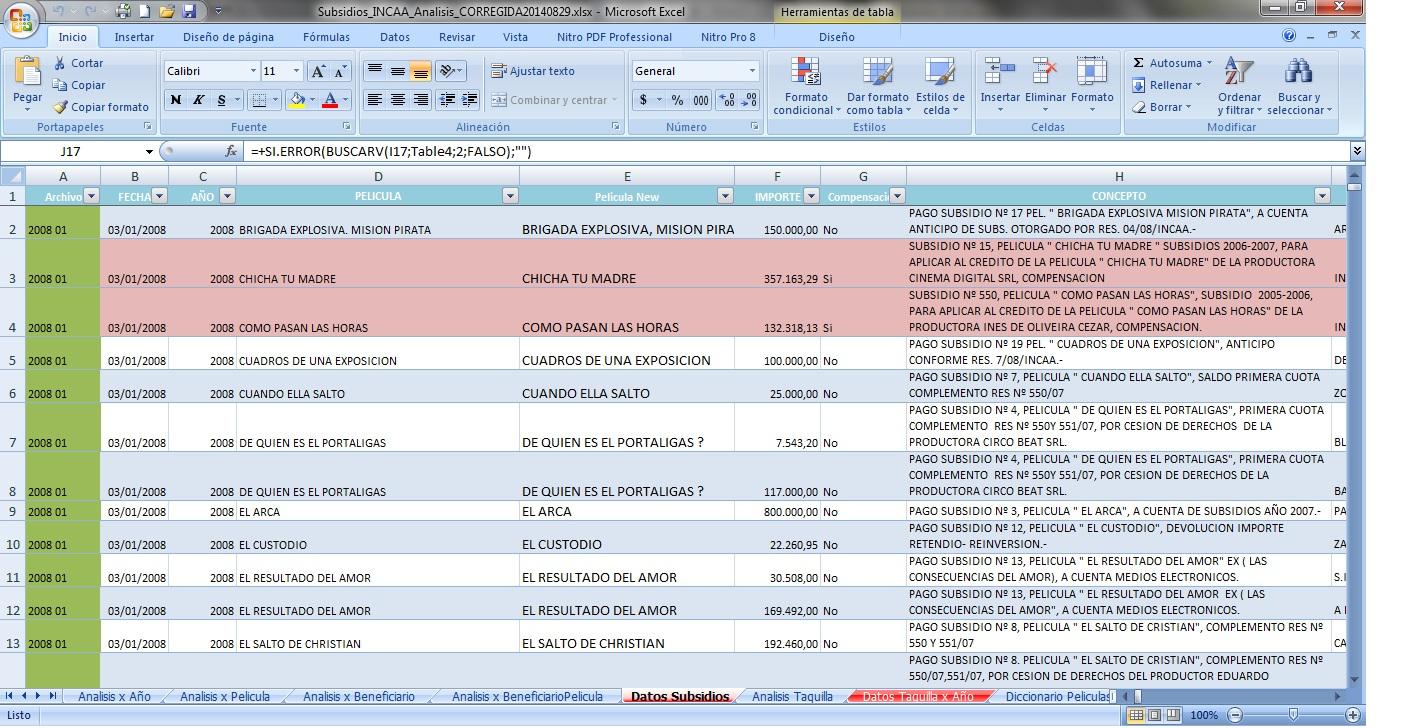
We built a special dataset with the raw data and this columns:
Date
Year
Name of Film
Amount of subsidy
Concept
Beneficiary
We checked all the TOTALS manually, in an organized internal check-a-thon between 5 of our team members. We detected in some cases the Concept column included a value named “compensations” , and after checking with INCAA (the official source) , we detected these amounts must be considered as negatives, so we inserted a new column considering these changes.
So we added the column “File” to indicate the origin of each row and the column “URL to Document Cloud” to keep the link to the document online (that we previously uploaded to Document Cloud).
To coordinate the collaborative checka-thon, we shared the dataset in a google spreadsheet distributing parts to each team member..
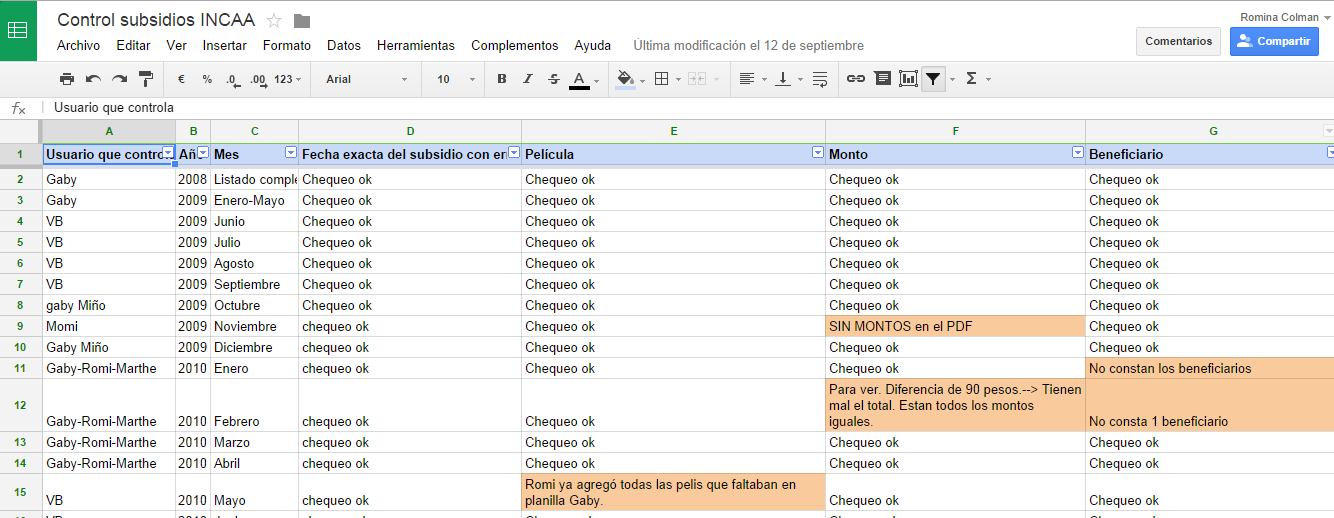
We registered the checked data and input the errors found to the application that would process again this PDFs and future ones, so it would learn from this cases.

Then we created a dictionary of equivalences in Movie names and Beneficiaries, as data comes without IDs of Film Names.
So each time we download a new period, the same movie or beneficiary is found and normalized with its correct name.
The dictionary of movie names corrects this problem, so we uploaded all the list of names to OPEN REFINE, and unified them using the “Cluster” method, and generating the new “corrected Movie name”.

And we saved this normalized dataset in Excel:

To create the Beneficiary dictionary we used the same procedure:

Then each time we add a new period we run the VLookup formula that corrects this problem in Movie Names and Beneficiaries.

Other Dataset was built from a source of each movie and its audience per year, so we added this to our database:
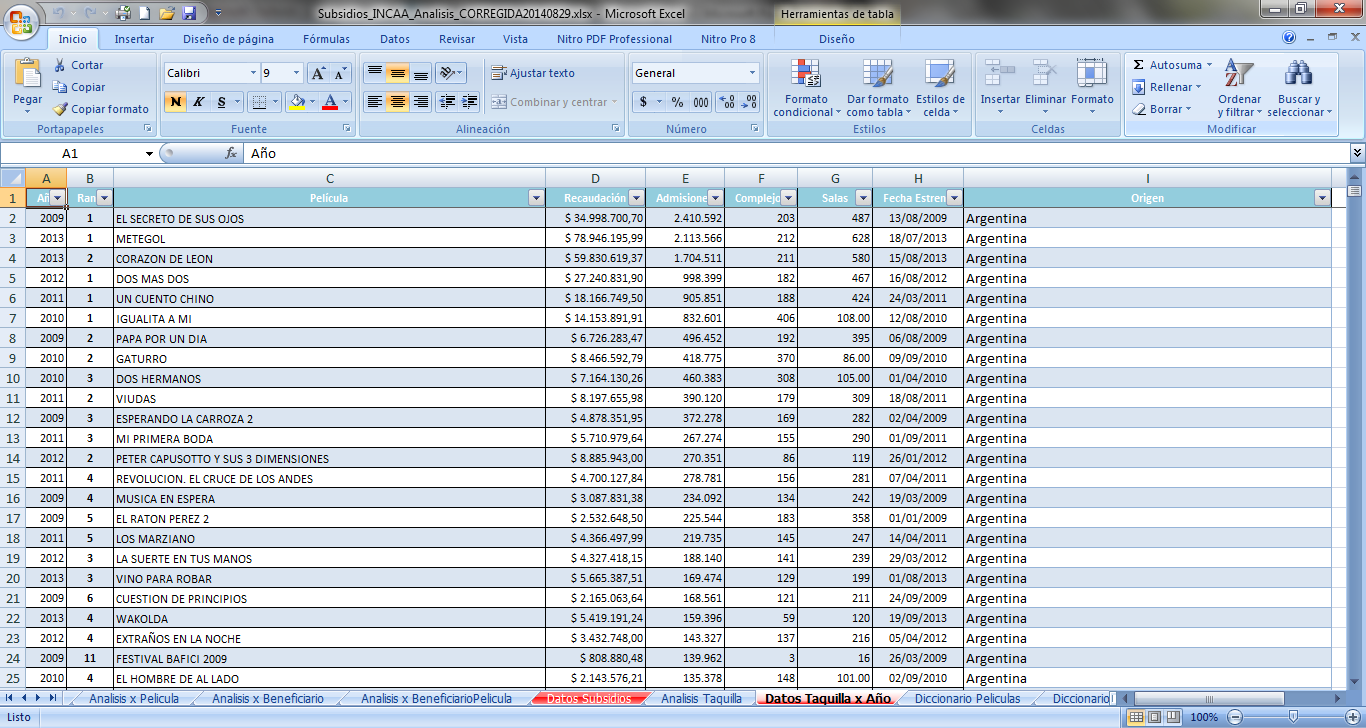
With this new dataset we created a pivot table by movie and year, where you can see the income per year (ticket sales), the position in the ranking for each movie, amount of theatres where it was published and a linear regression between income and audience represented in a chart.
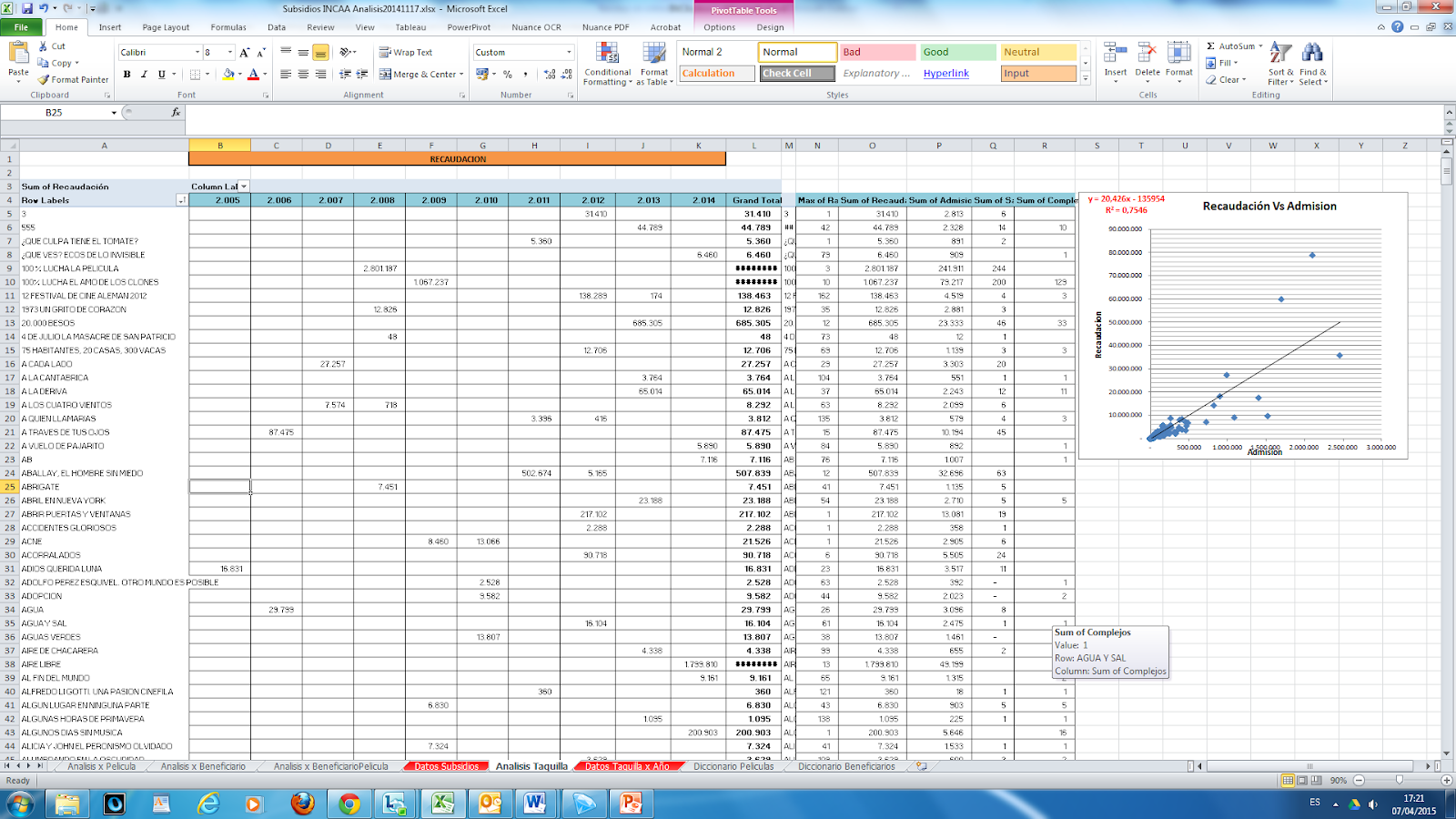
After this we built other pivot tables to get different analysis:
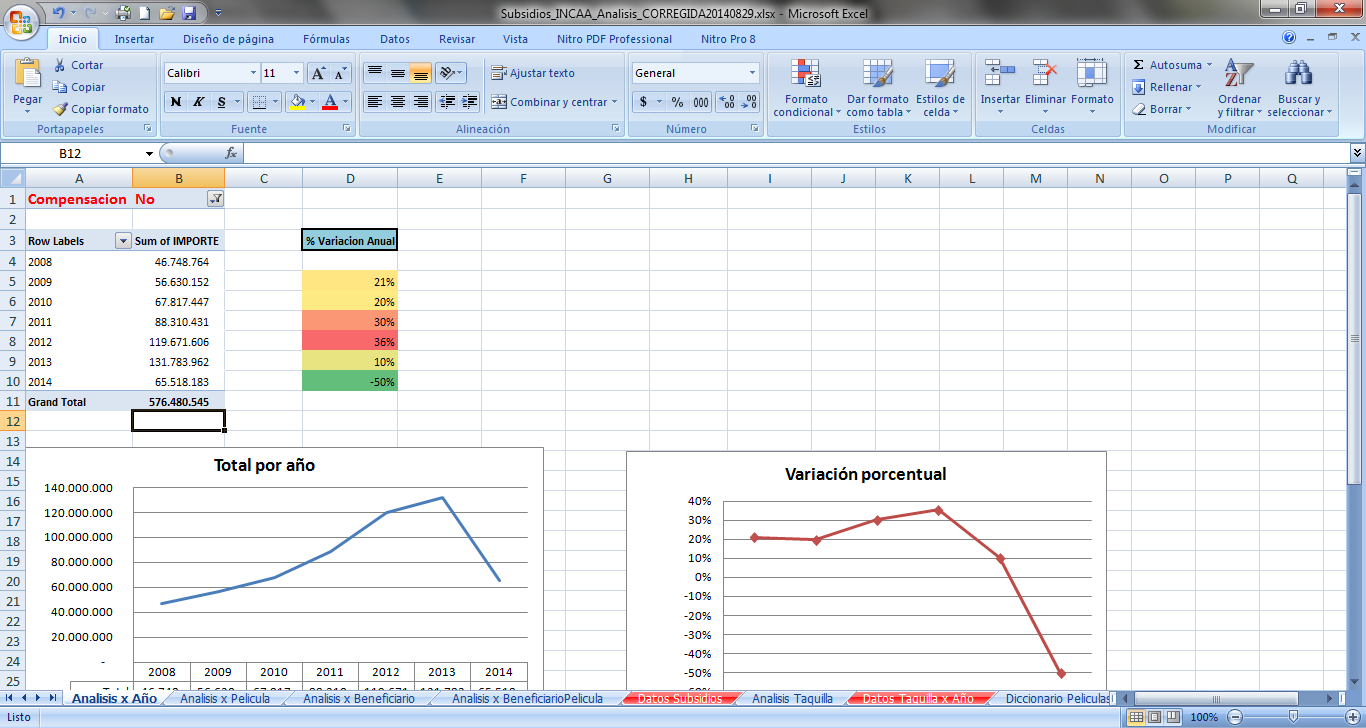
Per year analysis: amount of subsidy ordered by year and the annual percentage rate with their corresponding charts.
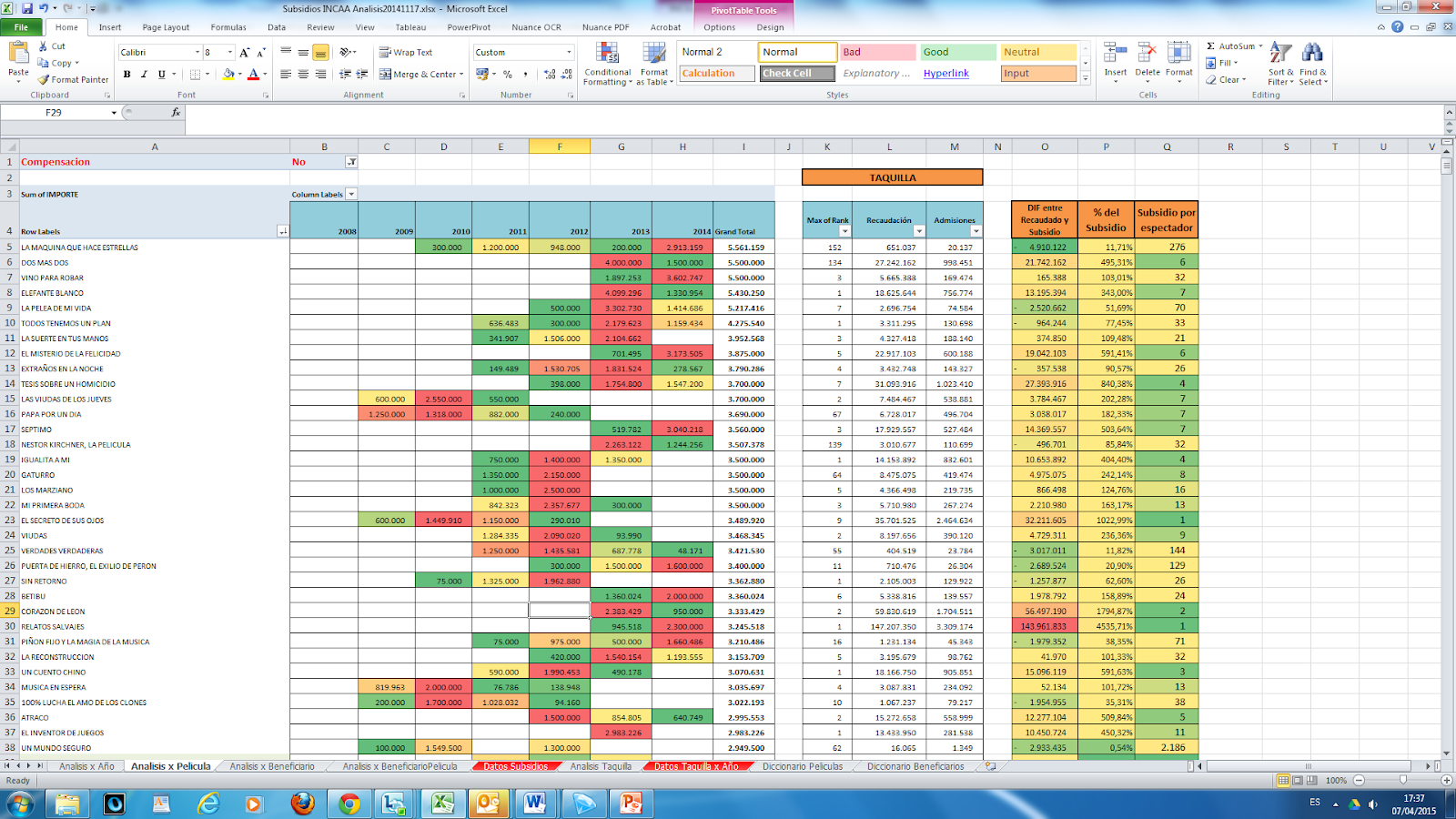
Per movie analysis: amount of subsidy ordered by total through all the years, then through a Vlookup crossed with “Taquilla (audience)” and compared with subsidy. This obtained a rate of subsidy per viewer, and that was used as the focus of the stories published.
We created a semaphore code of colors to help our journalists visually detect the relevant changes with scales that go in descending order from red to green.
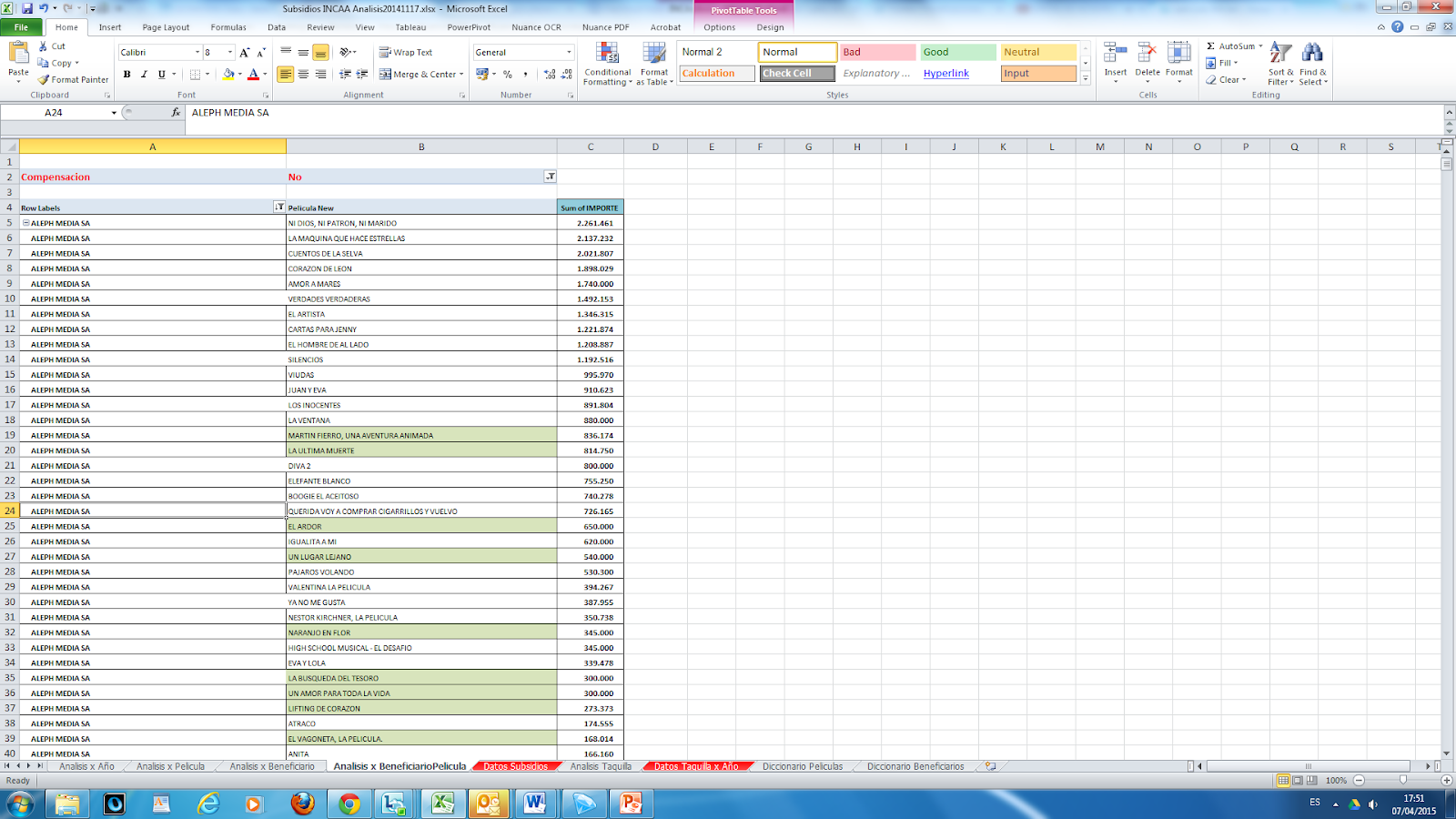
Per Beneficiary analysis: amount of subsidy ordered by total through all the years, also we created a table to see the annual percentage rate.
So that we can see the outliers. we created a semaphore code of colors to help our journalists visually detect the relevant changes with scales that go in descending order from red to green.

Per Beneficiary-Movie analysis: amount of subsidy ordered by Beneficiary and then by Movie.
Once we´ve done the corresponding data checking a table is extracted with the columns needed for the data visualizations and the designer takes this to build the interactive graphics.

And finally the series of articles:
http://www.lanacion.com.ar/1746332-subsidios-al-cine-el-insolito-costo-de-films-que-muy-pocos-ven
http://www.lanacion.com.ar/1777026-subsidios-al-cine-denuncias-fraudes-listas-negras-y-otras-polemicas-sobre-el-incaa