


A menos de 3 meses del lanzamiento de VozData, Knight-Mozilla OpenNews y LA NACION abren el código de esta plataforma para que cualquier persona u organización pueda crear su propio proyecto y clasificar documentos de manera colaborativa.
En este post, Gabriela Rodriguez, becaria del programa Knight-Mozilla OpenNews, cuenta su experiencia y explica cómo utilizar el código.
De VozData a CrowData: cómo liberamos el código, paso a paso
Empecé la beca de Open News en LA NACION con el pie derecho. Un proyecto buenísimo, llamado VozData, habia sido iniciado por el equipo LA NACION DATA, su programador Cristian Bertelegni y mi predecesor, Manuel Aristarán.
LA NACION tenía la tecnología para convertir en texto todo tipo de PDFs, pero se encontraron con un desafío aún mayor cuando dieron con miles de imágenes escaneadas en ese formato sobre las rendiciones de cuentas del Senado de los últimos 5 años.
Ninguna herramienta disponible podía transformar de manera confiable esa información en textos para ser reutilizados. Por eso, había que buscar el modo de hacerlo. Los PDFs escaneados tenían datos muy importantes como para dejarlos pasar. Trabajar su contenido permitiría saber, entre otras cosas, cuánto gastaba el Senado por rubro, los nombres de los adjudicatarios que recibían la mayor cantidad de dinero de esta institución y, por último, pero no menos importante: los lectores podrían tener una mirada global de lo que gasta en esta Cámara del Congreso Nacional.
The Guardian y ProPublica habían desarrollado proyectos colaborativos donde a la comunidad de lectores se le pedía ayuda para obtener los datos más relevantes de un gran conjunto de PDFs.
Inspirados en sus experiencias, el equipo de LA NACION DATA creó VozData, esta plataforma colaborativa a través de la cual las personas clasifican miles de documentos para transformarlos en una base con información comprensible.
Por eso, VozData es más que una simple herramienta tecnológica. Es una iniciativa que promueve la participación ciudadana y que puede ser usada por los periodistas para infinidad de proyectos en donde, debido al formato de los documentos, la información resulte difícil de extraer.
Además de poder publicar los datos que surgieran del trabajo colaborativo, también queríamos liberar el software que hizo posible a esta plataforma. Asi fue como VozData se convirtió en CrowData.
VozData fue desarrollado en Python con base en Django, un framework para desarrollo web. Manuel hizo un muy buen trabajo al diseñar la arquitectura para hacer posible que cualquier persona sin conocimientos de programación pueda agregar nuevos proyectos a la plataforma. El sitio cuenta con una interfase de administración (que utiliza el poder de Django Admin) donde es posible agregar un conjunto de PDFs y especificar los datos que quieren extraerse de ellos. Si alguno de esos datos pueden ser autocompletados (a partir de datos que ingresaron otras personas) entonces el sistema tiene una forma de crear categorías a partir de ellos y sugerir las categorías con similitud. Para esto utilizamos un algoritmo de similitud con la extension pg_trgm de Postgresql.
El nacimiento de CrowData
Nos organizamos para trabajar en VozData a traves de GitHub, un sitio web que sirve para compartir código, guardarlo con historial de cambios y utilizarlo como espacio que permite organizar múltiples tareas: errores vistos y nuevos requerimientos para la herramienta. Allí es donde nació CrowData, software libre de VozData.
Crowdata, tiene un espacio de administración de documentos y datos:

En este lugar, el staff del proyecto puede
- Administrar usuarios creados para la verificación de documentos
- Crear categorías deseables para los mismos.
- Levantar conjunto de documentos para verificar.
- Añadir y mirar documentos con sus datos verificados.
Cómo crear un proyecto
Para comenzar un proyecto nuevo en CrowData es necesario crear un conjunto de documentos al que llamaremos “Document Set” al cual deberá asignársele un nombre, descripción y una imagen que aparece en la pantalla principal:
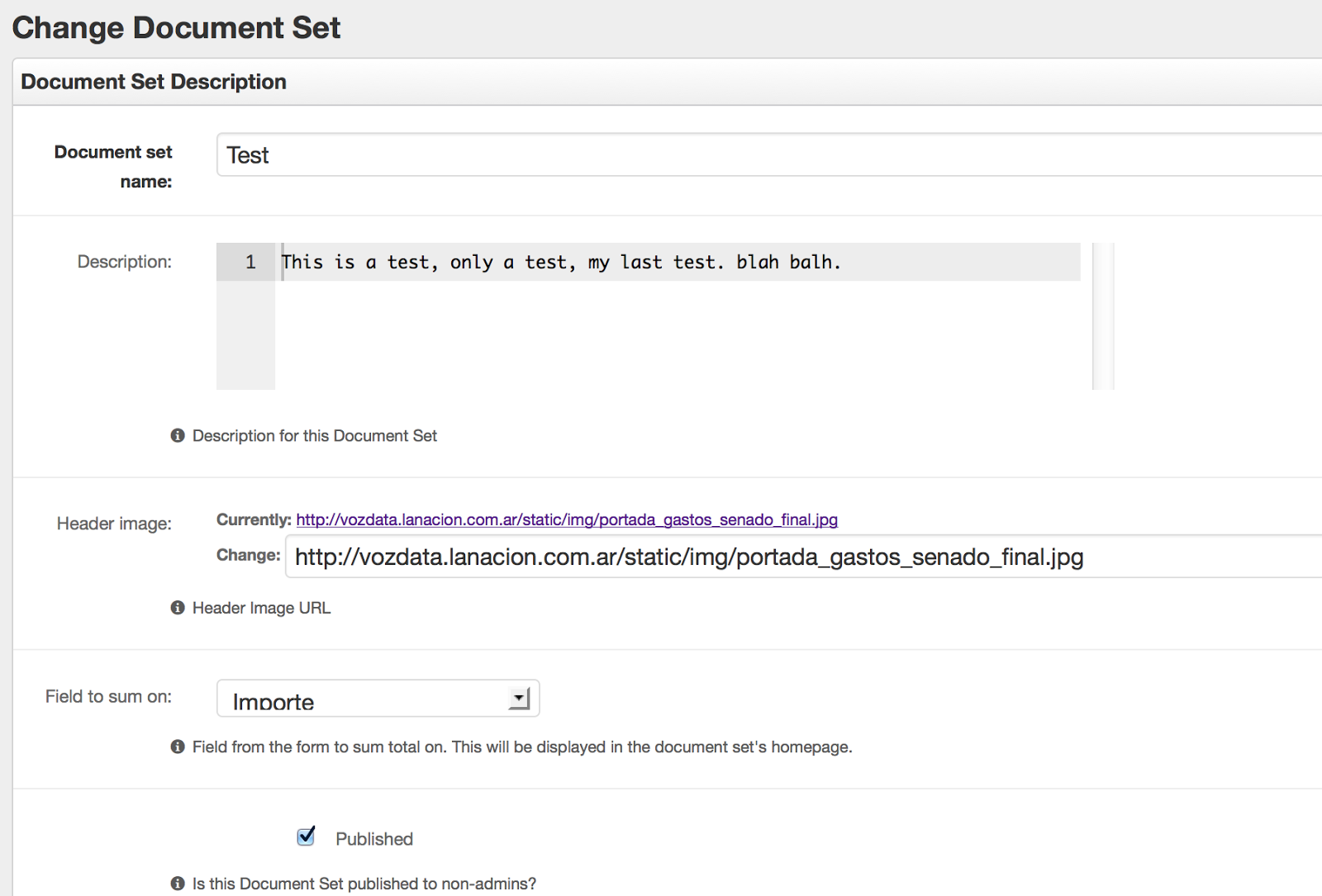
’Field to sum on’ es uno de los campos del formulario que debe ser desplegado como suma en la página principal del proyecto.
En este mismo lugar también se puede crear el formulario con los campos que queremos las personas completen al leer el documento. Para el primer proyecto de VozData, elegimos importe, adjudicatario y rubro, como campos obligatorios. Los opcionales fueron “Detalles del gasto”, “Comentarios” y la clasificación del documento por parte del usuario en 3 categorías posibles:

A continuación, se puede agregar el detalle de los rankings que luego aparecerán en la pantalla principal:
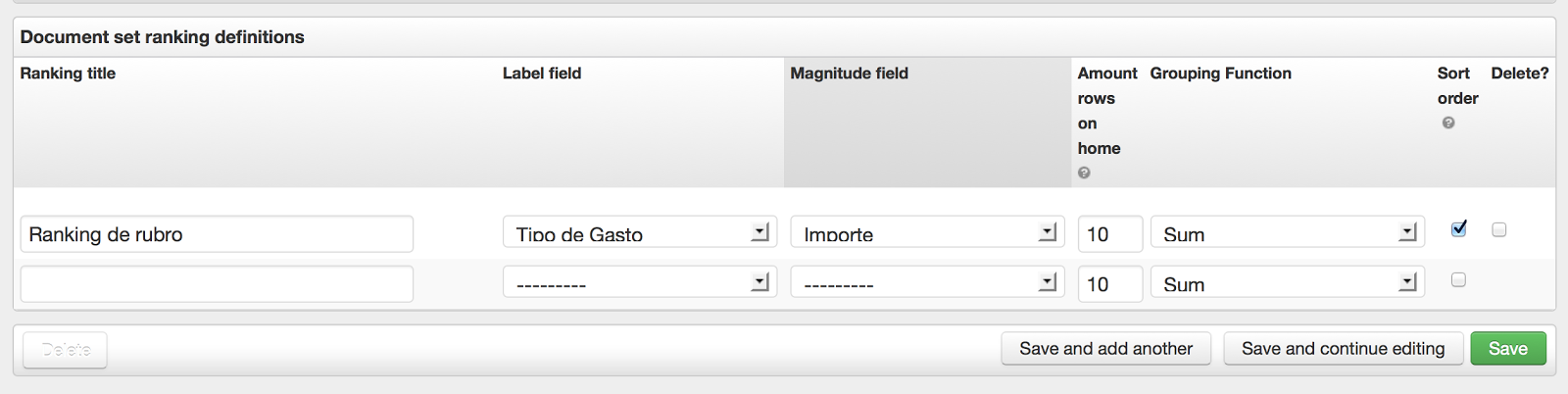
Cada caja de ranking va a mostrar la suma, promedio o cantidad de cualquier campo numérico y desplegar una lista en la página principal.
El siguiente paso es agregar los documentos. Para ello es necesario hostearlos en algún lugar. Con VozData usamos Document Cloud, una herramienta para periodistas y redacciones que permite subir y guardar archivos PDFs, así como también hacer anotaciones públicas o privadas en ellos.
Para cargar los documentos hay que crear un archivo CSV con una lista de las URL de cada uno de ellos y un título. Luego se deberá cargar este archivo en la administración de CrowData. Este proceso almacenará los documentos en la plataforma y los asociará al proyecto ‘Document Set’ creado anteriormente.

Importante: la administración del sitio tiene un botón que posibilita la descarga de todas las respuestas en formato CSV.
¿Y ahora?
Aún hay mucho más trabajo por hacer pero confiamos que más personas van a sumarse a CrowData y utilizarlo en sus redacciones. Si quieren utilizar el código, instalarlo, modificarlo, leer documentación o simplemente ver una demo sobre cómo funciona, pueden visitar la página web de Crowdata aquí.
En cuanto a VozData y su proyecto Gastos del Senado 2010-2012, aún queda trabajo por hacer: colocar los datos disponibles al público y hacer un chequeo de ellos para poder usarlos periodísticamente.
Por último, me gustaría mencionarles un elemento que debería estar presente en cualquier proyecto que utilice CrowData: la imprescindible tarea de trabajar con la comunidad. Cuando abrimos el primer proyecto, Gastos del Senado 2010-2012, organizamos dos “maratones cívicas” en donde invitamos ONGs , sociedad civil, universidades y lectores del diario en general, para chequear documentos. Así fue como alrededor de 500 personas lograron clasificar y revisar, de manera presencial o remota, más de 6500 documentos en menos de 3 meses.
Trabajar con la comunidad es clave y esto es algo que el periodismo no puede olvidar. Después de todo, contar mejores historias con datos y promover gobiernos más transparentes, depende de ello.
Más información
Maratón Cívica: VozData Gastos del Senado
VozData suma ONGs y Universidades
Maratón Cívica: nueva jornada para presentar datos públicos
VozData: ciudadanos aportaron su tiempo para monitorear el gasto público
Más de 500 voluntarios ayudaron a monitorear el gasto público