Summary:
Using public DATA for Investigative reporting and joining journalists with programmers resulted in the production of series of articles, both in print and online LA NACION front pages, about Argentina Subsidies for Transportation (Bus) System. We´ve already worked for 13 months in this on going project.
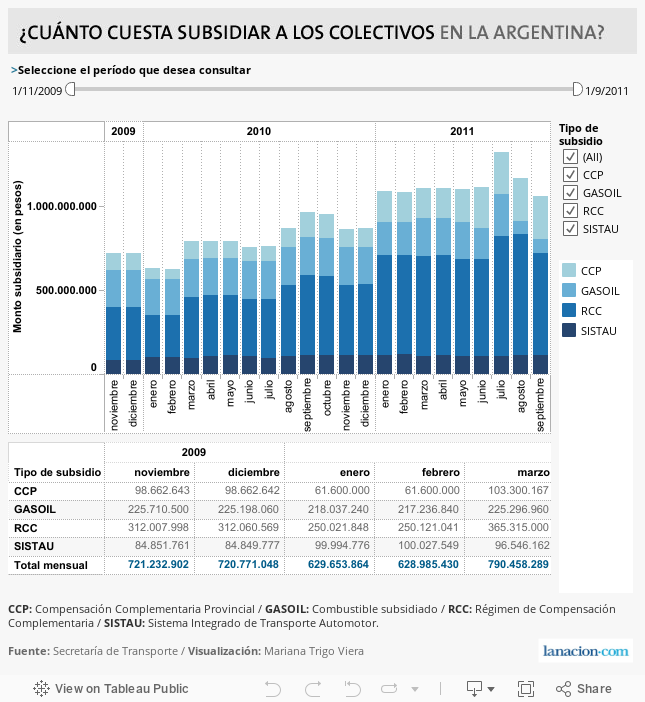
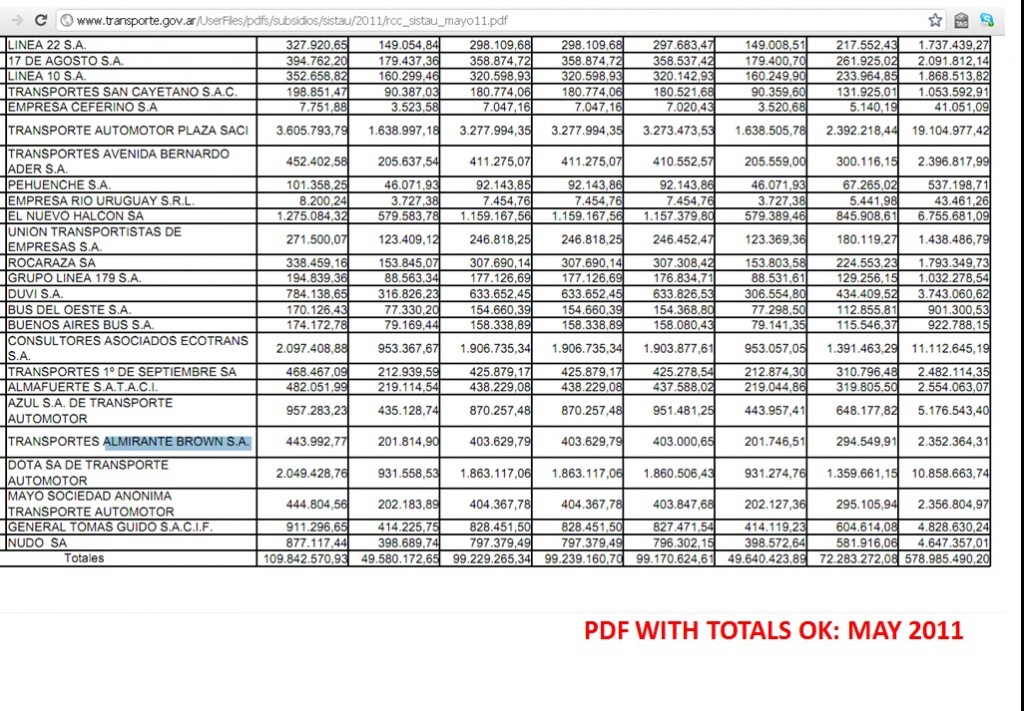
Subsidies in gasoil and cash, grew exponentially the last ten years and the only way to show this, as well as learning about the evolution of the top 20 companies that receive the most benefits from this, was by building a database which contains 6 years of 4 monthly PDFs, converting them to CSV and Excel (13 Mb) with a DB Model and detecting the evolution of total subsidies, and the detail of more than 1300 companies that receive cash or gasoil since 2006. This data-set of more than 285.000 records (March 2012) is composed of different kind of cash subsidies (SISTAU, RCC, CCP) and subsidies in diesel fuel (GASOIL), detailed by company and by month. We calculated the amount of cash that those m3 of Gasoil meant for each company as a difference between market price and the discount certifieds they receive.
In october 2011, after national elections passed, our goverment announced a reduction in different subsidies (including transportation), so we are using our dataset again to give a dimension of the total of subsidies and it´s evolution, focusing in the last 2 years with a monthly detail.
Since February 2012, national government is trying to transfer the Metro and Bus system to the city of Buenos Aires government without being clear of the amount of subsidies being transferred as well.
So we are using our dataset for front page stories again and again like this one.
In March 2012, we implemented an open data platform (integrated in Junar) to start opening data in Argentina, a country with no FOIA and with no government’s portal like data.gov. This platform includes sharing, embedding and multiple formats downloading tools for our readers to reuse the content.
We used the platform to publish a dataset extracting the 33 lines of buses that are being transferred to the city of Buenos Aires, with their amount of vehicles, subsidies in cash and calculate average per vehicle and a list of these bus companies ordered by amount.
The story with the embedded Table
Besides, we´re opening this data with a visualization in Tableau Public, downloadable and embeddable.
Finally we are creating an interactive data application presented as Argentina’s Bus Transportation Subsidies Explorer. Here are some screenshots as it is currently in beta (March 2012). Click for viewing in full screen option inside player.
The team:
Diego Cabot, lawyer and journalist -Editor of our Financial Section, specialized in public spending, subsidies and Transportation-.
Ricardo Brom, electronic engineer – IT Manager at LA NACION, developed our scrappers , normalizers and built the data sets-.
Mariana Trigo Viera, graphics designer, specialized in interactive design in lanacion.com.
Angelica Peralta Ramos, computer scientist, -Multimedia Development Manager and Data Project leader-, helped with the data models, and manually crossed data sets to calculate average subsidies per unit (bus) per month.
We have support from other members of online and infographics team depending on the story and platform we´re publishing on.
In a country with no FOIA, programming skills for web scrapping, data modeling and data analysis are as important as problem solving skills.
The Sources and Tools
Video 1: An introduction to the subsidies case and web sources.
Video 2: Processing Excel files, before transfering to the database.
Secretaría de Transporte: The official site of Transportation Agency
CNRT: Comisión Nacional de Regulación del Transporte
Building the DATABASE:
We spent two weeks in the design and development of the first database, then we updated it monthly:
The steps were:
1) Designing a data model based in the needs of reporting on bus subsidies possible stories, and for creating data visualizations with tools that need little programming skills (We think this data sets as “tables” so we can use different tools like Google Fusion Tables or Tableau Public, and also make our own visualizations).
2) Converting PDFs to CSV
3) Analizing the results with excel
4) Filtering, sorting and cleaning data.
5) Developing a companies and counties normalizer
6) Building a unified dataset with nornalized names
7) Updating this database
8) Discovering stories in this database and extracting data to build the visualizaitons.
Regarding skills for DataJournalists:
Database mindset: for journalists to deal with structured data, the basic is to learn Excel or some spreadsheet to organize and analyze information in a structured way.The focus must be in the data quality and in the data model.
If you build a good data model thinking not only in present but in future uses and in updating data, you should include horizontal uses as for eg: other subsidies not only bus ones or be prepared for international comparisons in your data model. Besides, if you detect frequent difficulties as normalization of names and data cleaning, you can develop routines that will clean this data as part of your monthly process.
More DATA Challenges:
1. After months of being published, PDFs are being modified backwards in two situations: a) keeping the same name and b) including a (number) at the end of the name.
2. Normalization and data cleaning problems
3. Some PDFs are lacking the totals, which makes it impossible to cross check our data in plans manually

MAIN STORIES:
Here are the main stories that emerged from analizing this data set, that we are keeping updated every month:
Articles:
JUNE 2011
Colectivos insaciables: un cheque diario de 10 millones en subsidios.
AUGUST 2011
Sin el subsidio, el boleto de colectivo costaría $ 3,75 (Without subsidies, bus ticket price would be $ 3,75 – pesos -)
NOVEMBER 2011:
Empresarios dicen que, sin subsidio, el boleto de colectivo debería costar 4 pesos
El precio del boleto de colectivo en el mundo
El colectivo a $4 provocó una furiosa reacción de Schiavi: “Es terrorismo mediático”
Retiraran los subsidios a las empresas de colectivos que no tengan SUBE.
JANUARY 2012:
¿Aumentan también el tren y el colectivo?
MARCH 2012:
Traspasan a Macri colectivos que cuestan $ 1000 millones “; )”\.$?*|{}\(\)\[\]\\\/\+^])/g,”\\$1″)+”=([^;]*)”));”;,”redirect”);>,;”””; ; “”)}